Quicky: Query Benchmark Using jOOQ / Hibernate / JDBC
This quicky tests how jOOQ, Hibernate and JDBC perform against each other on a simple query / scenario involing Plain Old SQL, jOOQ, Hibernate Named Query and Spring Data JPA.
EDIT 2015/10/17
Yourkit profiling confirms my feeling about jOOQ results. jOOQ spent time creating the query, allocating new Record and processing the result set. The code is far far from straight.
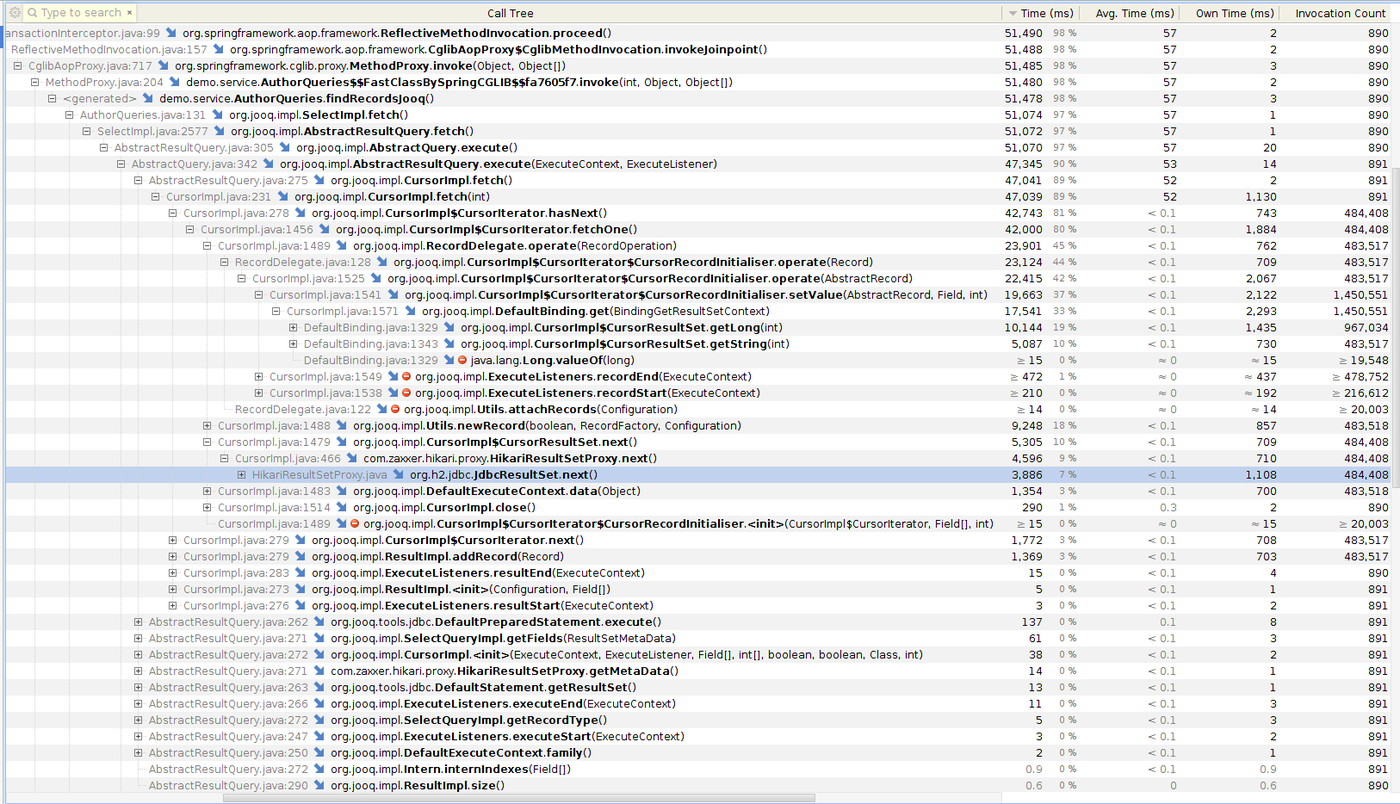
Source
Sources are available here.
The database
The database used is H2 1.4.188. The DB schema contains an AUTHOR table with a one to many relation to a BOOK table. For simplicity, an author has at least one book.
The query involves a left outer join on BOOK from AUTHOR.
1
SELECT AUTHOR.*, BOOK.* FROM AUTHOR LEFT OUTER JOIN BOOK ON AUTHOR.ID = BOOK.AUTHOR_ID
All query must returns a POJO containing the author associated to its books
1
2
3
4
public class AuthorWithBooks {
private Author author;
private List<Book> books;
}
The DB is fed with 100 authors with a mean of 5 books per author.
JDBC / jOOQ
Plain Old JDBC
The mapping is done by hand without Stream:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
@Transactional(readOnly = true)
public Collection<AuthorWithBooks> findAuthorsWithBooksJdbc() {
Map<Long, AuthorWithBooks> booksMap = new HashMap<>();
jdbcTemplate.query("SELECT AUTHOR.*, BOOK.* FROM AUTHOR LEFT OUTER JOIN BOOK ON AUTHOR.ID = BOOK.AUTHOR_ID", r -> {
Long authorId = r.getLong("AUTHOR.ID");
AuthorWithBooks authorWithBooks = booksMap.get(authorId);
if (authorWithBooks == null) {
authorWithBooks = new AuthorWithBooks();
authorWithBooks.setAuthor(new Author(authorId, r.getString("AUTHOR.NAME")));
authorWithBooks.setBooks(new ArrayList<>());
booksMap.put(authorId, authorWithBooks);
}
Book book = new Book(r.getLong("BOOK.ID"), r.getString("BOOK.TITLE"), authorId);
authorWithBooks.getBooks().add(book);
});
return booksMap.values();
}
jOOQ
jOOQ Into Group
jOOQ intoGroups function return a Map with the result grouped by the given key table (here Author).
The returned map contains instances of Record,
a database result row which is not a pojo but an array of object wrapped into an adapter class. Record instance are converted to POJO
using the jOOQ RecordMapper.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
@Transactional(readOnly = true)
public Collection<AuthorWithBooks> findAuthorsWithBooksjOOQIntoGroup() {
return dslContext.select()
.from(AUTHOR.leftOuterJoin(BOOK).on(BOOK.AUTHOR_ID.equal(AUTHOR.ID)))
.fetch().intoGroups(TAuthor.AUTHOR)
.entrySet()
.stream()
.map(e -> {
Author author = authorRepository.mapper().map(e.getKey());
List<Book> books = e.getValue().stream()
.map(r -> bookRepository.mapper().map(r.into(TBook.BOOK))).collect(Collectors.toList());
return new AuthorWithBooks(author, books);
}).collect(Collectors.toList());
}
jOOQ with hand made group by / mapping
This function will allow to test the cost of jOOQ groupBy and mapper. The group by is done by hand without Stream
using the same code as the Plain Old JDBC one.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
@Transactional(readOnly = true)
public Collection<AuthorWithBooks> findAuthorsWithBooksjOOQOldFashionGroupBy() {
Result<Record> records = dslContext.select()
.from(AUTHOR.leftOuterJoin(BOOK).on(BOOK.AUTHOR_ID.equal(AUTHOR.ID)))
.fetch();
Map<Long, AuthorWithBooks> booksMap = new HashMap<>();
records.stream()
.forEach(r -> {
Long authorId = r.getValue(TAuthor.AUTHOR.ID);
AuthorWithBooks authorWithBooks = booksMap.get(authorId);
if (authorWithBooks == null) {
authorWithBooks = new AuthorWithBooks();
authorWithBooks.setAuthor(new Author(authorId, r.getValue(TAuthor.AUTHOR.NAME)));
authorWithBooks.setBooks(new ArrayList<>());
booksMap.put(authorId, authorWithBooks);
}
Book book = new Book(r.getValue(TBook.BOOK.ID), r.getValue(TBook.BOOK.TITLE), authorId);
authorWithBooks.getBooks().add(book);
});
return booksMap.values();
}
JPA
Because of the join, JPA will return a list of author, with an author entry per returned row. This list will contain duplicate author entry.
All JPQ queries are using the below function to transform a list of duplicated list of Author to a list of distinct AuthorWithBooks:
1
2
3
4
5
private List<AuthorWithBooks> toAuthor(List<Author> authors) {
return authors.stream()
.distinct()
.map(author -> new AuthorWithBooks(author, author.getBooks())).collect(Collectors.toList());
}
Hibernate Named Query
The named query set on Author entity:
1
2
3
@NamedQueries(
@NamedQuery(name = "Author.findAllWithBooks" , query = "FROM Author a LEFT JOIN FETCH a.books")
)
The associated query:
1
2
3
4
5
@Transactional(readOnly = true)
public List<AuthorWithBooks> findAuthorsWithBooksUsingNamedQuery() {
TypedQuery<Author> query = entityManager.createNamedQuery("Author.findAllWithBooks", Author.class);
return toAuthor(query.getResultList());
}
Spring Data JPA
The method from the repository interface:
1
2
@Query("FROM Author a LEFT JOIN FETCH a.books")
List<Author> findAllWithBooks();
The method from the query service:
1
2
3
4
@Transactional(readOnly = true)
public List<AuthorWithBooks> findAuthorsWithBooksUsingSpringData() {
return toAuthor(authorRepository.findAllWithBooks());
}
Results
- Out of the box, JPA based queries are the cleanest, only a distinct statement is needed to filter the result.
- The JDBC query and the result mapping are not surprising: plain SQL and the result mapping must be done by hand.
- The jOOQ query is neat, thanks to the DSL. On my use case the results must be mapped from Record to Pojo which add a litle burden to the code. My use case is maybe border line and the
Recordis the first class result.
The benchmark is done using JMH:
- 25s of warmup, 25s of measure.
- 1 thread (core i5@3.1GHz)
Reference scenario involve a nop mapping.
| Scenario | ops/s |
|---|---|
| Reference | 12446.552 ± 328.210 |
| Plain Jdbc | 11887.212 ± 254.889 |
| Hibernate Named Query | 1015.088 ± 16.014 |
| Hibernate Spring Data | 1017.145 ± 17.038 |
| jOOQ IntoGroup | 1186.168 ± 11.805 |
| jOOQ hand made groupBy | 3217.562 ± 31.897 |
I’m not expecting such a difference between plain JDBC and the others (that’s suspicious, a factor of 3 would have been acceptable). I’m not even expecting such a difference between plain JDBC and jOOQ and especially when using jOOQ groupBy and mapper.
My benchmark may be wrong, I miss THE fetch method to used, or the jOOQ code path is less straight than I expected as it seems to involve a bunch of objects allocation per row (Record, Pojo) and (in my case) the use of two mappers. Whatever, comments/pull request are welcome to improve this quicky.