Introduction à Splunk

Splunk est un applicatif d’intelligence opérationnelle. Il extrait et indexe des datas et offre des features de data mining: extraction, exploitation et visualisation.
C’est un applicatif closed source fondé sur un business model payant en relation avec la volumétrie de data indexée par jour.
Dans cet article nous allons installer Splunk, configurer l’extraction de logs et de metrics, exploiter les logs dans une recherche simple, afficher des metrics sur un graphique puis créer une alerte associée. Pour finir je concluerai en faisant un parallèle avec les solutions open sources.
Splunk en quelques mots
Splunk c’est sous la plume du marketing:
You see servers and devices, apps and logs, traffic and clouds. We see data—everywhere. Splunk® offers the leading platform for Operational Intelligence. It enables the curious to look closely at what others ignore—machine data—and find what others never see: insights that can help make your company more productive, profitable, competitive and secure. What can you do with Splunk? Just ask.
Le modèle de licence et de cout de Splunk est fondé sur la volumétrie de log/jour et [sur les éditions/features].(http://www.splunk.com/en_us/products/pricing.html). Il offre plusieurs éditions Enterprise / Cloud / Light dont une version free] qui limite les features et la volumétrie de logs à 500MB/day. Splunk supporte Linux, Windows, Solaris, Mac OS, FreeBSD, AIX.
Splunk, hormis donc la version free mais limité, n’est pas gratuit et est closed source. Il a pour lui de posséder des fonctions d’extraction, d’indexation et d’exploitation intégrées dans un seul outil là où pour avoir un équivalent Open Source, nous devrions intégrer plus d’un outils.
Scenario
L’objectif va être d’exploiter les logs applicatifs et les metrics d’une application Java:
- Affichage des logs
- Affichage sur un même graphique de la mémoire heap utilisée et de la mémoire heap max
- Création d’une alerte sur la mémoire utilisée
Les logs et les metrics seront écrits dans des fichiers de logs en utilisant logback. Il y aura deux types de fichiers en sortie (et donc deux appenders). Le premier stockera les logs dans un format faiblement structuré texte, il a pour but d’être lisible par des Humains. Le second stockera dans le format JSON pour être lu par les Machines. Je publierai un article portant sur le logging expliquant ce choix.
Les fichiers de logs seront stockés dans /var/log/myapp. Pour contraindre l’article à une taille raisonnable,
Splunk et l’application pourront accéder au même répertoire de logs. Donc pas de forwarder.
Vous pourrez trouver les sources de cet article sur github.
Installation de Splunk
Installation du package
Je passe par docker pour minimiser les impacts sur ma machine. Attention, le téléchargement du package nécessite d’être enregistré sur leur site. Le dockerfile se résume à l’installation du package debian:
1
2
3
FROM ubuntu:14.04
ADD package/splunk-6.2.3-264376-linux-2.6-amd64.deb /tmp/splunk-6.2.3-264376-linux-2.6-amd64.deb
RUN sudo dpkg -i /tmp/splunk-6.2.3-264376-linux-2.6-amd64.deb
Construction de l’image:
1
sudo docker build -t nlab/splunk .
Pour un controle plus fin, je lance le container sur la commande bash
1
sudo docker run -t -p 8000:8000 -v $HOME/splunk/var:/opt/splunk/var/lib/splunk -v $HOME/splunk/apps:/opt/splunk/etc/apps -v $HOME/splunk/log:/var/log/myapp -i nlab/splunk /bin/bash
Splunk se lance par défaut sur le port 8000. Son répertoire d’installation est /opt/splunk/. Je mappe les répertoires suivants:
$HOME/splunk/var => /opt/splunk/var/lib/splunk: contient les datas (indexes…)$HOME/splunk/apps => /opt/splunk/etc/apps: contient les applications splunk$HOME/splunk/log => /var/log/myapp: contient les logs à indexer
Ensuite dans le container je lance Splunk par cette commande:
1
/opt/splunk/bin/splunk start --accept-license --answer-yes
Et voila, splunk est lancé et accessible via l’adresse http://localhost:8000.
Configuration
Splunk peut être configuré de plusieurs façons: ligne de commande, fichiers de configuration, interface REST, interface web. Les fichiers de configuration de splunk sont de type ini.
Il est conseillé de centraliser les ajouts dans une application Splunk plutôt que de modifier directement les fichiers de configuration $SPLUNK/etc/system.
La création d’une application est simple et peut se faire en ligne de commande ou via l’interface web.
Application
Nous allons créer l’application nlab via l’interface web /opt/splunk/etc/apps/nlab/
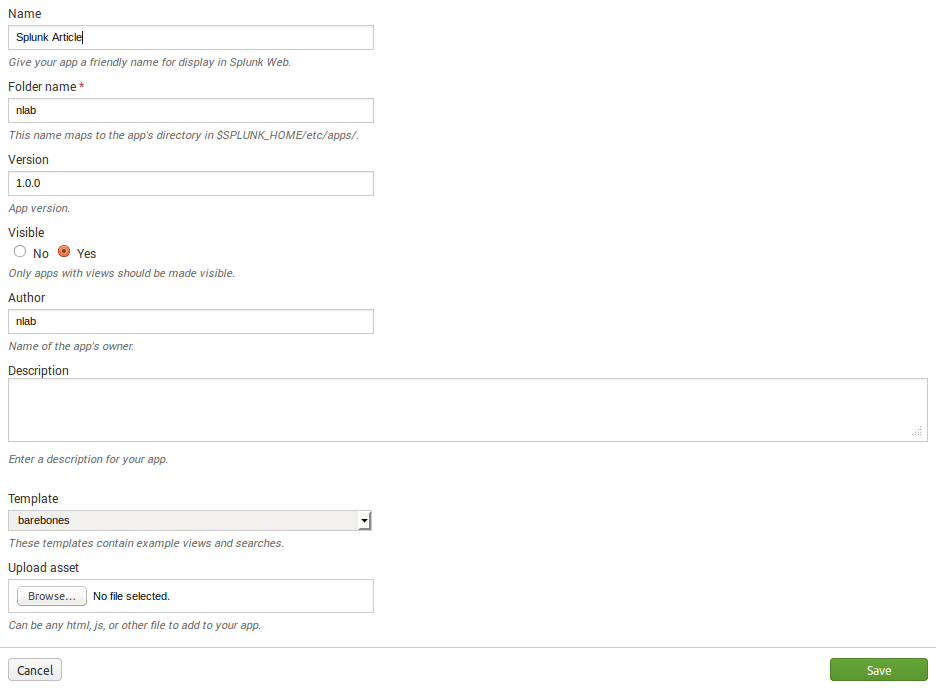
Indexes
Nous créons deux indexes NLAB_LOGS et NLAB_METRICS qui vont servir à stocker respectivement les logs et les metrics
La configuration des indexes est stockée dans le fichier indexes.conf
qui est stocké dans le répertoire de l’application /opt/splunk/etc/apps/nlab/local.
Pas de fioriture, nous ne mettons que le strict minimum: le répertoire de stockage des données suivant leurs états.
1
2
3
4
5
6
7
8
9
[NLAB_LOGS]
homePath = $SPLUNK_DB/nlab_logs/db
coldPath = $SPLUNK_DB/nlab_logs/colddb
thawedPath = $SPLUNK_DB/nlab_logs/thaweddb
[NLAB_METRICS]
homePath = $SPLUNK_DB/nlab_metrics/db
coldPath = $SPLUNK_DB/nlab_metrics/colddb
thawedPath = $SPLUNK_DB/nlab_metrics/thaweddb
Le nom de la section permet de nommer l’index. Les propriétés homePath, coldPath et thawedPath définissent le répertoire de stockage des données suivant leurs états.
Pour plus d’information sur la notion de staging et de bucket, voir la page suivante How the indexer stores indexes
Inputs
L’application va générer deux fichiers de logs: app.json.log et metrics.json.log.
La configuration des inputs est stockée dans le fichier inputs.conf
qui est stocké dans le répertoire de l’application /opt/splunk/etc/apps/nlab/local.
Les fichiers à monitorer sont définis dans le nom de la section.
[monitor://
]
- This directs Splunk to watch all files in
. can be an entire directory or just a single file. - You must specify the input type and then the path, so put three slashes in your path if you are starting at the root (to include the slash that goes before the root directory).
Des wildcards peuvent être utilisés dans le path pour monitorer des logs d’applicatifs suivant le même formalisme ou par typologie eg. /var/log/httpd/*_access.
1
2
3
4
5
6
7
[monitor:///var/log/myapp/app.json.log]
index=NLAB_LOGS
sourcetype=NLAB_JSON
[monitor:///var/log/myapp/metrics.json.log]
index=NLAB_METRICS
sourcetype=NLAB_JSON
La propriété index permet de définir l’index de destination et la propriété sourcetype permet de caractériser le type de traitement à appliquer.
Primarily used to explicitly declare the source type for this data, as opposed to allowing it to be determined via automated methods. This is typically important both for searchability and for applying the relevant configuration for this type of data during parsing and indexing.
C’est une bonne pratique d’indiquer à Splunk le type de logs / traitement à appliquer plutôt que de le laisser inférer celui-ci (même s’il est relativement bon à ce jeu là).
Processing Properties (Props)
Les processing properties permettent de créer, entre autre, les sourcetype.
La configuration des props est stockée dans le fichier props.conf
qui est encore une fois stocké dans le répertoire de l’application /opt/splunk/etc/apps/nlab/local.
1
2
3
4
[NLAB_JSON]
INDEXED_EXTRACTIONS=JSON
KV_MODE=none
AUTO_KV_JSON=false
INDEXED_EXTRACTIONS: Tells Splunk the type of file and the extraction and/or parsing method Splunk should use on the file.KV_MODE: Used for search-time field extractions only. Specifies the field/value extraction mode for the data.AUTO_KV_JSON: Used for search-time field extractions only. Specifies whether to try json extraction automatically.
L’extraction des fields est donc faite à l’indexation.
Exploitation
Nous sommes prêt à exploiter nos logs.
Affichage des events
Nous allons pouvoir rechercher les events par index:
- Query:
index="nlab_logs"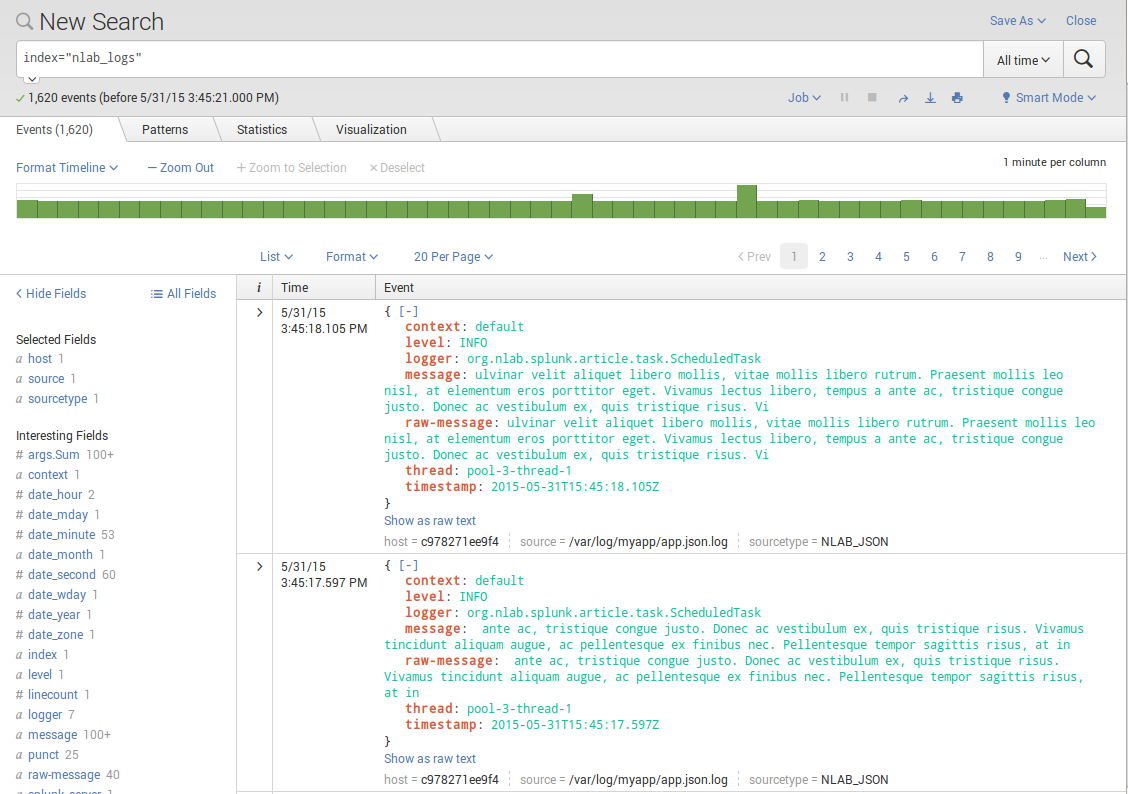
- Query:
index="nlab_metrics"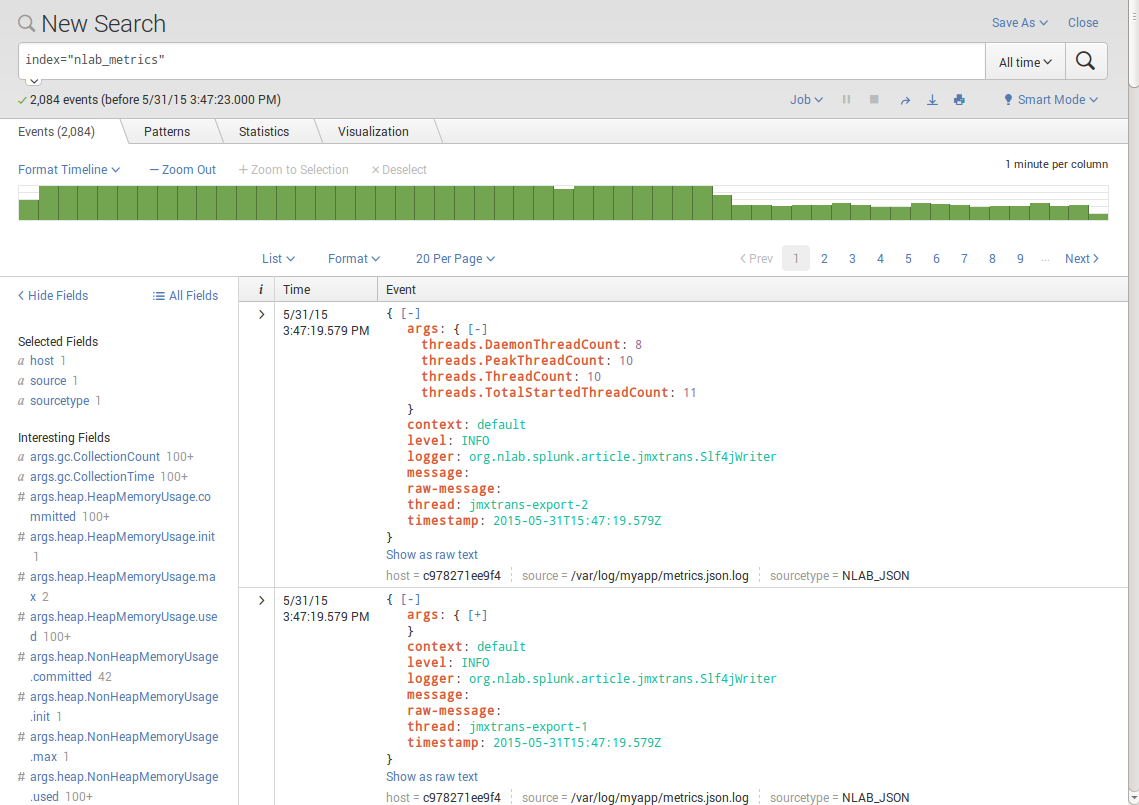
Affichage des logs
L’affichage des events est brute. Une table dédiée peut être créé n’affichant que les fields d’intêrets. Nous utilisons pour cela la fonction table
qui prend une liste de fields: index="nlab_logs" | table timestamp level thread logger message:
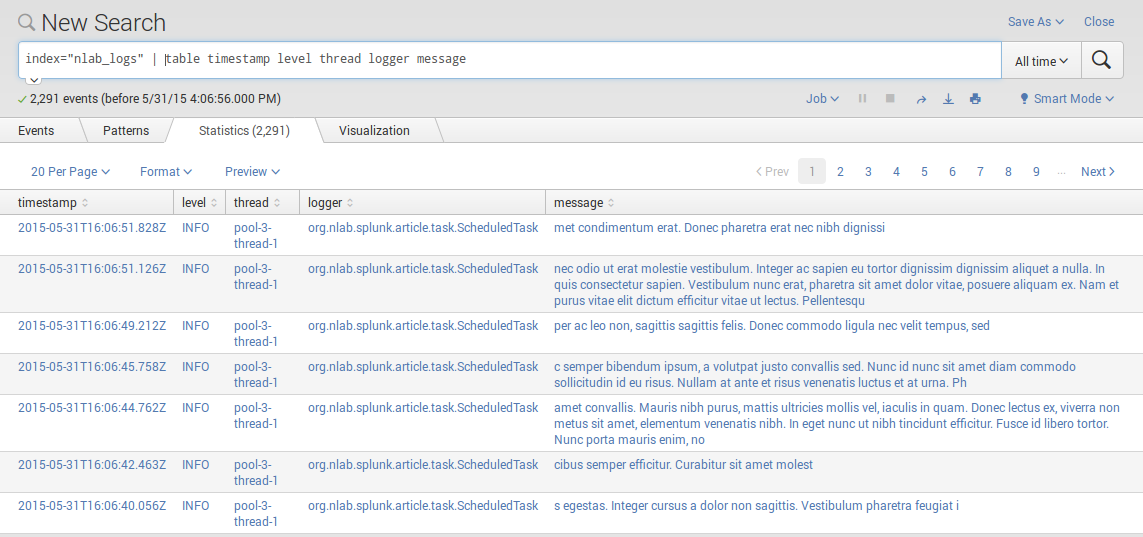
Cet affichage pourrait être encore raffiné en ne cherchant que les logs de niveau ERROR: index="nlab_logs" level=ERROR | table timestamp level thread logger message.
Graphing
Le premier graphe que nous allons afficher est celui de la mémoire utilisée.
Pour ce faire nous pouvons utiliser la query suivante index="nlab_metrics" | timechart max("args.heap.HeapMemoryUsage.used")
qui utilise la fonction timechart.
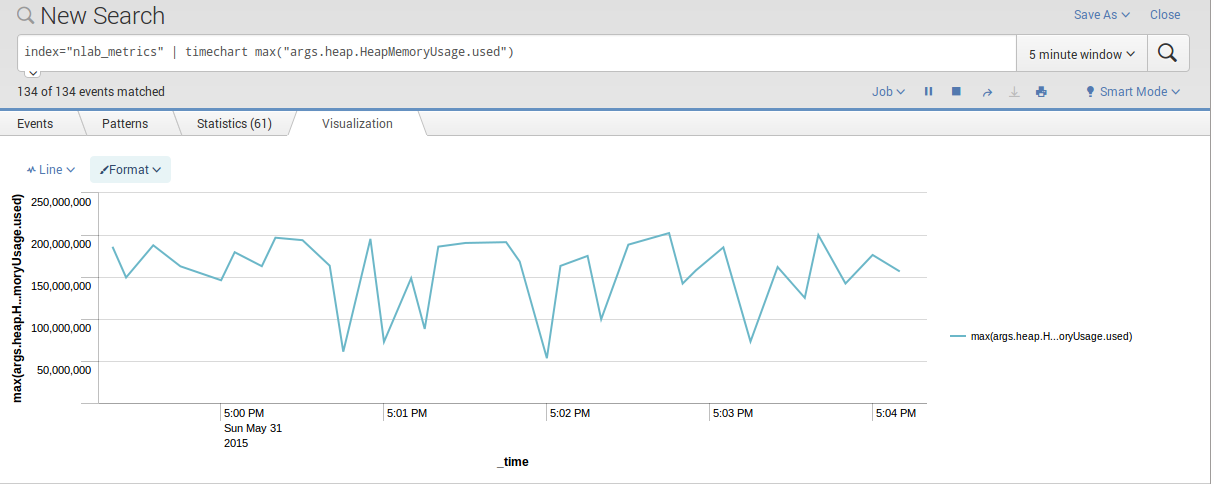
La query suivante index="nlab_metrics" | timechart max("args.heap.HeapMemoryUsage.max") permet logiquement de faire de même avec la mémoire max.
Notre histoire se corse quand il s’agit d’afficher les deux series sur un même chart:
Splunk Enterprise transforming commands do not support a direct way to define multiple data series in your charts (or timecharts). However, you CAN achieve this using a combination of the stats and xyseries commands.
Ce qui traduit avec nos données donne la query suivante:
1
2
3
4
index=nlab_metrics | stats max("args.heap.HeapMemoryUsage.used") as memoryUsed, max("args.heap.HeapMemoryUsage.max") as memoryMax by _time,source
| eval s1="args.heap.HeapMemoryUsage.used args.heap.HeapMemoryUsage.max" | makemv s1 | mvexpand s1
| eval yval=case(s1=="args.heap.HeapMemoryUsage.used",memoryUsed,s1=="args.heap.HeapMemoryUsage.max",memoryMax)
| eval series=source+":"+s1 | xyseries _time,series,yval
Pour donner le graphe suivant:
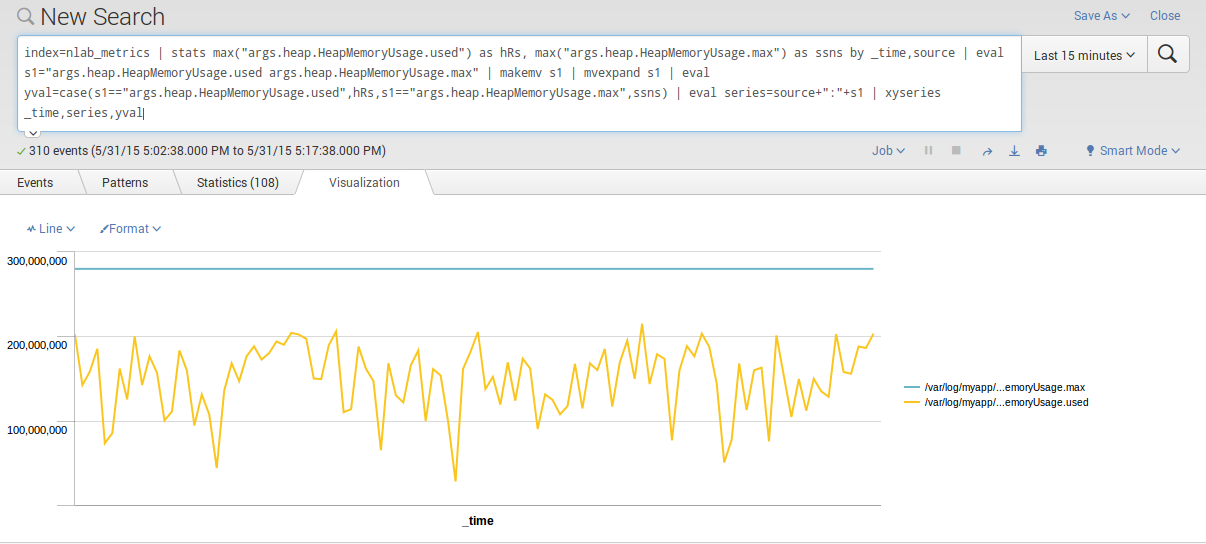
La query est compliquée pour un besoin a priori trivial. Combiner les graphes avec Graphite se résume à définir une liste de fonctions séparée par un ampersand.
Ce qui donnerait la query (HTTP) suivante alias(args.heap.HeapMemoryUsage.used, 'Used')&alias(args.heap.HeapMemoryUsage.max, 'Max').
Simple et très efficace.
Par contre Splunk sait combiner des graphes suivant un critère de regroupement. Par exemple la query suivante affiche la mémoire libre par host:
1
2
index=nlab_metrics "args.heap.HeapMemoryUsage.used"="*" earliest=-60s| eval free=('args.heap.HeapMemoryUsage.max' - 'args.heap.HeapMemoryUsage.used')
| timechart avg(free) by host
Même si dans le cas présent nous n’avons qu’un host:
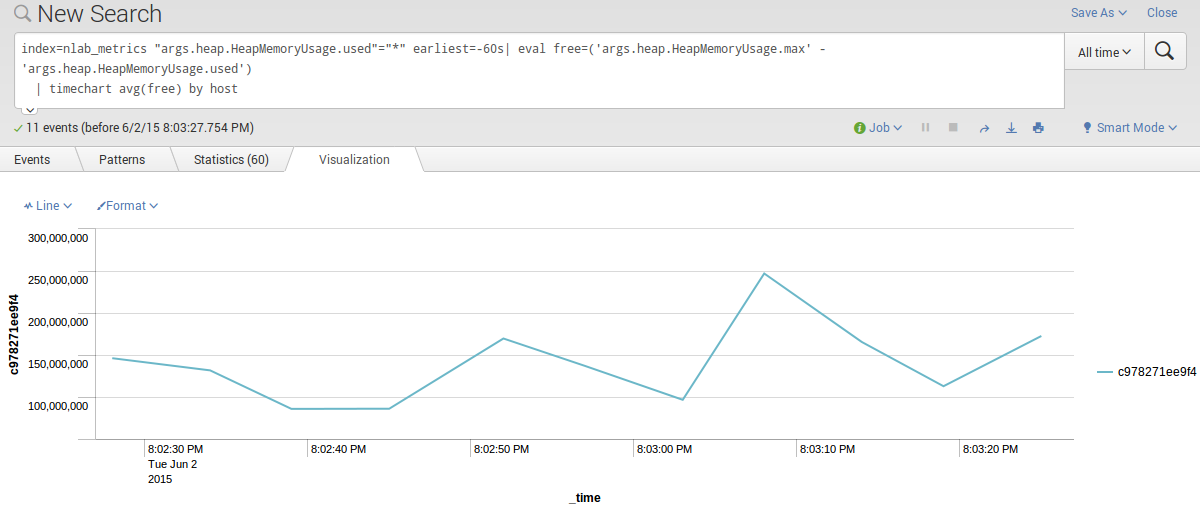
Alerting
La création d’alerte se fait en définissant une query de recherche puis en créant une alerte à partir de celle-ci.
L’alerte que nous définissons se fera sur la mémoire JVM restante :
1
2
index=nlab_metrics "args.heap.HeapMemoryUsage.used"="*" earliest=-60s| eval free=('args.heap.HeapMemoryUsage.max' - 'args.heap.HeapMemoryUsage.used')
| eval threshold=free - 'args.heap.HeapMemoryUsage.max' * 0.15 | search threshold < 0
"args.heap.HeapMemoryUsage.used"="*": retourne tous les events ayant ce field valuéearliest=-60s: entre maintenant et -60s dans le passéeval free=('args.heap.HeapMemoryUsage.max' - 'args.heap.HeapMemoryUsage.used'): définition du fieldfreeégale à la mémoire libreeval threshold=free - 'args.heap.HeapMemoryUsage.max' * 0.15: définition du fieldfreeégale à la mémoire libre moins le seuil d’alerte fixé à 15% de la mémoire maxsearch threshold < 0: permet de filtrer les résultat suivant le threshold
Nous la sauvons en tant qu’alerte
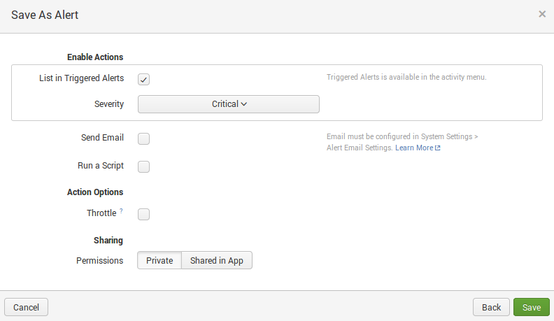
Le système d’alerte se basant sur l’index, nous aurions pu créer une alerte sur l’index de logs associée au niveau de log ERROR donnant une query de ce type
index=nlab_logs level=ERROR earliest=-60s
Conclusion
Dans cet article nous n’avons survolé qu’une partie des possibilités offertes par Splunk:
- Splunk peut être clusterisé et répliqué suivant différentes topologies (eg. noeuds indexer, noeuds searcher).
- L’extraction des logs sur un serveur distant peut et doit être réalisée en utilisant un
Splunk Universal Forwarderqui est configuré en utilisant les mêmes mécanismes que ceux que nous avons vus. - Dans sa version Enterprise, il permet la gestion d’un ensemble de forwarders et de leurs configurations qui est donc centralisées et poussées du serveur vers le forwarder. La configuration est associée via un système de classificateur (par host, ip…)
- Splunk possède un écosystème d’apps et addons, citons notamment Splunk App for Unix and Linux
- Il permet la création de dashboard et il offre également un SDK
- L’aspect exploitation des logs peut être poussé en utilisant un ensemble de commandes et de fonctions
- […]
Qu’en est-il de l’existant Open Source ?
Existant Open Source
La présentation Monitoring Open Source pour Java avec JmxTrans, Graphite et Nagios est une bonne base présentant les outils Open Source nécessaires à notre besoin.
Metrics / Graphing
- Jmxtrans: Extraction des metriques exportées via JMX
- Graphite: Stockage et exploitation des metrics (calculs…), rendu (image, texte…). Graphite se compose de de trois applicatifs Python carbon (listener), graphite (UI), whisper (stockage RRD)
- Graphana: Il permet de constituer des dashboards autour de metrics Graphite (entre autre); ce projet est une perle.
Logs
- Logstash, flume: Collecte des logs
- Elasticsearch: Stockage, query
- Kibana: Exploitation des logs, visualisation et extraction.
Alerting
- Seyren: Application d’alerting qui se branche à graphite. Il possède un nombre appréciable de canaux. Il nécessite MongoDB.
La liste n’est pas exhaustive et il y a bien sur des variations, InfluxDB au lieu de graphite, Nagios au lieu de Seyren… La liste des fonctionnalités des projets listés ci-dessous, une fois mis bout à bout, est conséquente. Cependant le nombre d’applicatifs impliqués dans la chaine est important et la mise en haute disponibilité de chacun de ces élements pourrait faire l’objet d’un sujet dédié (eg. pour graphite The architecture of clustering Graphite).
Pour m’être frotté à la mise en place de cette stack open source avec en prime sa puppetisation, le faire ne fut pas nécessairement rapide et simple (et c’est sans parler de l’aspect haute disponibilité). Le résultat était satisfaisant surtout sur les aspects monitoring. Difficile de justifier l’installation d’un mongodb pour le seul besoin de stocker des alertes.
Demeurait l’impression que le dashboard opérationnel était constitué de trois applications (Graphana, Kibana, Seyren) non intégré.
Pour conclure
Le point majeur est à mon sens l’aspect intégré et homogène de la solution. Qui a un coût bien sur.
Splunk a rempli son rôle est un minimum d’installation et de manipulation et les mêmes principes sont appliqués du serveur au forwarder.
L’aspect exploitation des logs est à première vu satisfaisant. Reste à valider que cette typologie d’accès au log se rapproche d’une consultation vi.
Mon bémol porte pour l’instant sur les aspects graphing qui bien qu’il soit riche ne me semble pas égaler les possibilités et la facilité offertes par Graphite.